Create Trusted Web3 Identities
Build stronger communities with Cabana Labs. Go beyond anonymous avatars and faceless interactions with a robust framework that unlocks value in your community.








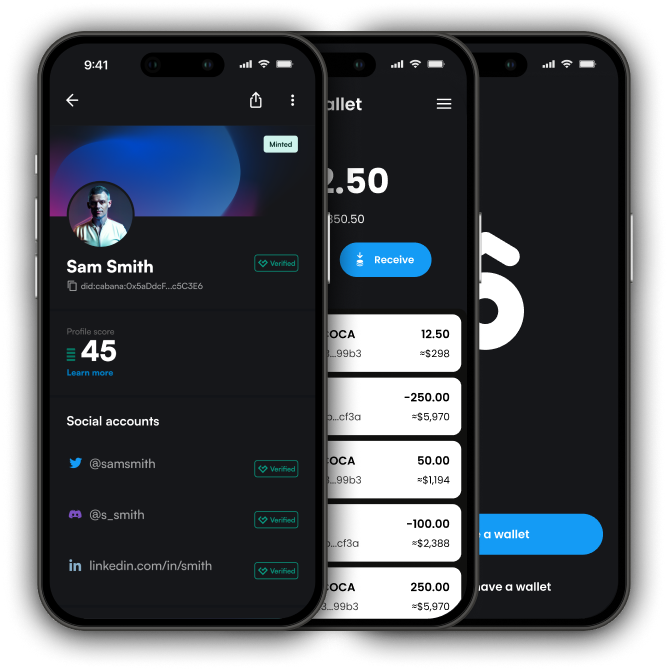
Trust Scores
Trust Scores offer a rich tapestry of information – make informed decisions, secure interactions, and establish meaningful connections. These measurements offer a view into each identity's trustworthiness in the digital world.

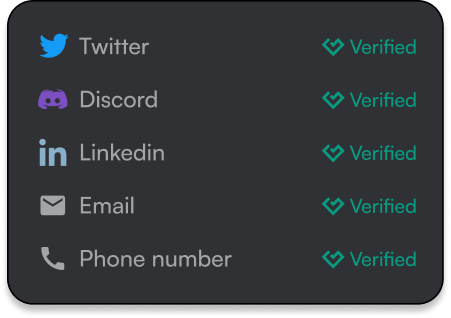
Measure of verified information such as email, phone, social media, and KYC documents.

Peer-based rating of past interactions and transactions that include feedback, reviews and ratings.

Financial value pledged for identity legitimacy. Trust those with skin in the game.

A measure of commitment to account security, and a strategic awareness to risk vs convenience.
Identity Building
Motivate users to invest in their digital identities for greater access, opportunities, and community standing.




Cabana SDK
Effortlessly embed Cabana Identity into existing protocols, platforms and projects, enriching user experience and unlocking additional community value.
Cabana Identity thrives on collaboration. We provide the building blocks. You shape the future.
Decentralized Key Management
- Powered by smart contracts on Oasis Sapphire
- Sign & verify transactions across blockchains.
- Issue and verify Verifiable Credentials
- Verify ZK Proofs
- Verify Passkeys
Cryptographic Algorithms
- ES256K (Secp256k1) - Bitcoin, Alephium, ICP, Ethereum, All EVM-Compatible, and more
- ES256 (Secp256r1) - JWT, Passkeys
- Ed25519, Sr25519 - Zcash, Cosmo, Cardano, Polkadot, and more
- BLS12-381 - ZK Proofs







")

Build With Us
- Web3 Profiles (Verifiable + Selective Disclosure)
- Smart Wallets (Account Abstraction)
- Identity Verification (Privacy-Preserving)
- Node Validators
- Fair Airdrops
- Governance Roles
It's Time to Build with Trust
Are you ready to create a thriving, secure, and rewarding community? Contact us today to discover how Cabana Identity can unlock your community’s full potential.





